Hoy os quiero hablar de una situación que viví el otro día cuando haciendo un refactor quise dejar de usar primitivos y los problemas que esto me causo.
¿Por qué debemos evitar usar primitivos?
Existe un smell llamado Primitive Obsession
el cual consiste en utilizar primitivos para representar conceptos que no lo
son en absoluto. Los ejemplos más habituales son utilizar un string para representar un
número de teléfono o un entero para representar un precio.
Tengo que decir que considero este smell como “entendible” es fácil caer en la tentación de representar los datos de la forma más habitual y no “perder” un poco más de tiempo creando clases que representen su significado.
Algunos de los beneficios de no usar primitivos son:
- Las operaciones relacionadas con nuestros datos estarán todas en el mismo lugar y no repartidas por el código.
- El código será capaz de expresar por sí mismo su significado, no os lo mismo ver una lista de enteros que una lista de números de teléfono.
¿Como remplazar los primitivos?
Una vez conocido el smell pensemos en como solucionarlo.
Por suerte no es un smell muy complicado en su concepto y bastará con crear clases que nos permitan representar de una forma más clara el concepto que estabamos representando con primitivos.
Para lograr este objetivo debemos hablar del concepto Value Object que como su propio nombre indica nos van a permitir crear clases que representen y se diferencian por su valor.
Caso de uso real remplazando primitivos por Value Objects
Después de tanto texto vamos a ver algo de código para representar el porqué de este post.
Imaginemos que tenemos que implementar un repositorio de usuarios que nos permita, entre otras cosas, buscar a un usuario.
Para ello, y como siempre, vamos a aplicar TDD y ver las distintas fases del mismo. Empecemos por un test:
from expects import equal, expect
from typing import List
from test_data import TestData
from user import User
from users_repository import UsersRepository
class TestUsersRepository:
def test_find_one_user(self) -> None:
user = TestData.a_user()
users: List[User] = [user]
# for testing purposes we're going to inject some users to the repo
users_repository = UsersRepository(users)
current_user = users_repository.find_by_name(user.name)
expect(current_user).to(equal(user))
Una vez que tengamos los tests y estemos en la fase Red de TDD debemos lograr volver lo antes posible a la fase Green, para ellos vamos a necesitar una clase object mother para crear usuarios:
from user import User
class TestData:
@staticmethod
def a_user() -> User:
return User(name="any-user", email="any-email@abc.xz", age=20)
Esta clase a su vez necesitará que exista el concepto de User:
from dataclasses import dataclass
@dataclass
class User:
name: str
email: str
age: int
Y por último vamos a crear nuestro repositorio con la implementación más sencilla posible:
from typing import List, Optional
from user import User
class UsersRepository:
def __init__(self, users: List[User]) -> None:
self.users = users
def find_by_name(self, user_name: str) -> Optional[User]:
for user in self.users:
if user.name == user_name:
return user
return None
Refactor
El ejemplo es realmente sencillo, generamos un repositorio de usuarios en memoria, los almacenamos como lista y para buscar iteramos sobre ella hasta encontrar al usuario en cuestión.
Esto quiere decir que la complejidad de nuestro método es O(n) lo que significa
que si esta lista contiene decenas de miles de usuarios nuestro método es todo menos eficiente.
En su lugar vamos a almacenar nuestros usuarios en un diccionario que nos permita encontrar a nuestro usuario
de forma instantánea, con una complejidad de O(1) y sin importar el número de usuarios.
Para nuestro diccionario vamos a utilizar el Email de cada cliente como key y
para no perder mucho tiempo vamos a asumir que es de tipo str.
Una vez más empezamos cambiando los tests y que estos nos guíen en el refactor:
from expects import equal, expect
from typing import Dict
from test_data import TestData
from user import User
from users_repository import UsersRepository
class TestUsersRepository:
def test_find_one_user(self) -> None:
user = TestData.a_user()
users: Dict[str, User] = {user.email: user}
# for testing purposes we're going to inject some users to the repo
users_repository = UsersRepository(users)
current_user = users_repository.find_by_email(user.email)
expect(current_user).to(equal(user))
Esto nos obligará a cambiar la implementación de nuestro repositorio:
from typing import Dict, Optional
from user import User
class UsersRepository:
def __init__(self, users: Dict[str, User]) -> None:
self.users = users
def find_by_email(self, email: str) -> Optional[User]:
return self.users.get(email)
Value Object como key en lugar de primitivos
Y llegamos al punto realmente interesante del post.
Como una primera iteración está bien que usemos un str como key de nuestro diccionario de usuarios, pero
¿realmente es lo más correcto? Imagina que unos meses después vuelves sobre este
mismo código y ves users: Dict[str, User]. Es imposible saber de primeras que
necesitas usar como key en el diccionario y eso es un problema.
¿Por qué no le damos un poco de semántica a nuestro código y utilizamos un tipo
que realmente exprese cuál es nuestra key? Como veremos a continuación no es
complicado de conseguir y nuestro código será mucho más claro.
from expects import equal, expect
from typing import Dict
from test_data import TestData
from user import Email, User
from users_repository import UsersRepository
class TestUsersRepository:
def test_find_one_user(self) -> None:
user = TestData.a_user()
users: Dict[Email, User] = {user.email: user}
# for testing purposes we're going to inject some users to the repo
users_repository = UsersRepository(users)
current_user = users_repository.find_by_email(user.email)
expect(current_user).to(equal(user))
Después creamos la entidad Email para poder usarla dentro de la clase User:
from dataclasses import dataclass
@dataclass
class Email:
email: str
@dataclass
class User:
name: str
email: Email
age: int
Esto nos obligará a actualizar nuestro UserBuilder:
from user import Email, User
class UserBuiler:
def __init__(self) -> None:
self._name = "any-name"
self._email = Email("any-email@abc.xz")
self._age = 1
def build(self) -> User:
return User(name = self._name, email=self._email, age=self._age)
Y por último nuestro repositorio de usuarios:
from typing import Dict, Optional
from user import Email, User
class UsersRepository:
def __init__(self, users: Dict[Email, User]) -> None:
self.users = users
def find_by_email(self, email: Email) -> Optional[User]:
return self.users.get(email)
¡Pero no todo iba a ser coser y cantar!
Cuando hayamos acabado con nuestro refactor deberíamos tener un error en nuestro test tal que así:
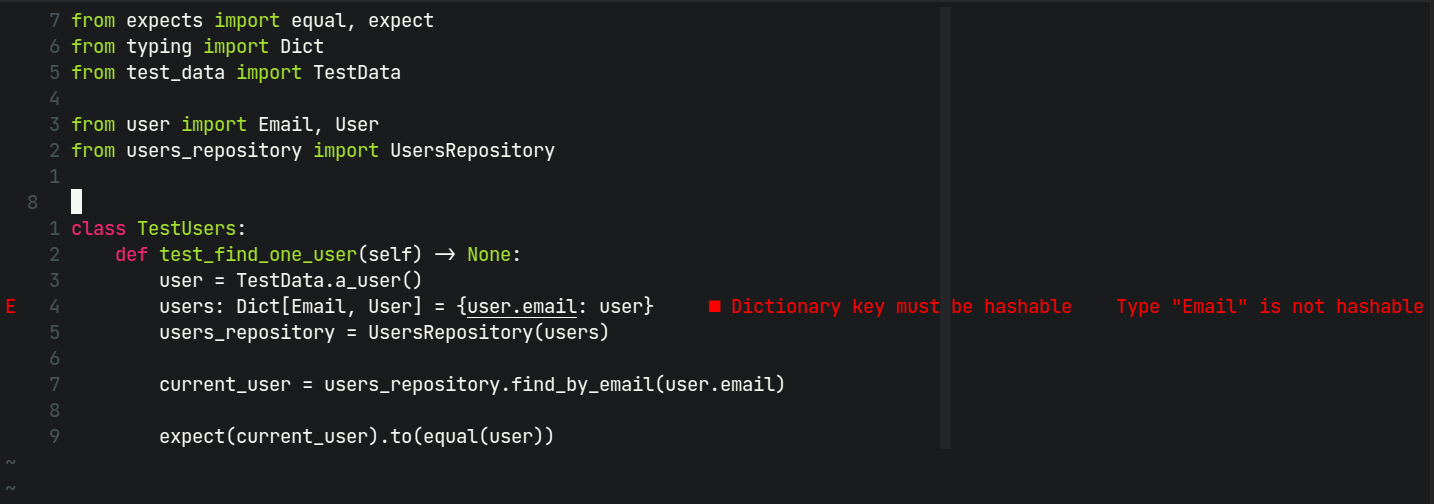
Este error se debe a que no es posible usar tipos en nuestras keys que no sean
hasheables o lo que es lo mismo que no tengan implementado el método
__hash__.
Como veremos a continuación este no es un problema para nada grave y tendremos varias posibilidades para solucionarlo.
Solucionemos el problema
Entendido el problema solo queda buscar una solución. Yo voy a proponer tres distintas para entender bien como solucionarlo por nosotros mismos antes de delegar esta responsabilidad en el propio lenguaje de Python.
Implementamos el método hash
La forma más evidente es implementar nosotros mismo el método __hash__:
from dataclasses import dataclass
@dataclass
class Email:
email: str
def __hash__(self) -> int:
return hash(self.email)
@dataclass
class User:
name: str
email: Email
age: int
Inicialmente la implementación hacía uso de la función id, pero como me comentó @iblancasa aquí no es correcto pese a que
funcione. Lo correcto es usar la función hash.
Usemos los parámetros de configuración de @dataclass
Por suerte para nosotros estamos haciendo uso de dataclasess las cuales
incorporan una serie de configuraciones que nos van a simplificar un montón
la vida. Un ejemplo es decirle a nuestra @dataclass que nos implemente tanto
el método __eq__ (implementado por defecto) como el método __hash__
from dataclasses import dataclass
@dataclass(unsafe_hash=True)
class Email:
email: str
@dataclass
class User:
name: str
email: Email
age: int
Hagamos nuestra clase inmutable
Aún podemos un poco más allá y definir nuestra clase como inmutable a través del
parámetro frozen de @dataclass
from dataclasses import dataclass
@dataclass(frozen=True)
class Email:
email: str
@dataclass
class User:
name: str
email: Email
age: int
Por entender un poco que ocurre por debajo debemos saber que:
- Si
eqyfrozenson ambostrue, @dataclass generara el método hash() por nosotros. - Si
eqestrueyfrozenesfalse,__hash__()tendrá el valorNone, convirtiendo a la clase en no hashable. - Si
eqesfalse, el método__hash__()no se modificara lo que significa que se usara el método__hash__()de la clase madre.
Así pues la forma más sencilla de hacer una clase hashable es convirtiéndola en inmutable, lo que además encaja perfectamente con la definición de lo que es un Value Object.
DISCLAMER: En Python toda clase que herede de una clase inmutable, esta debe ser inmutable también.
Conclusiones
Hoy hemos podido ver como es preferible utilizar Value Objects para representar nuestros modelos en lugar de primitivos, pero que esto tiene un precio a pagar que es incrementar un poco la complejidad y tener que programar un poco más de código.
!Un saludo!